Results


We address Embodied Reference Understanding, the task of predicting the object a person in the scene refers to through pointing gesture and language. This requires multimodal reasoning over text, visual pointing cues, and scene context, yet existing methods often fail to fully exploit visual disambiguation signals. We also observe that while the referent often aligns with the head-to-fingertip direction, in many cases it aligns more closely with the wrist-to-fingertip direction, making a single-line assumption overly limiting. To address this, we propose a dual-model framework, where one model learns from the head-to-fingertip direction and the other from the wrist-to-fingertip direction. We introduce a Gaussian ray heatmap representation of these lines and use them as input to provide a strong supervisory signal that encourages the model to better attend to pointing cues. To fuse their complementary strengths, we present the CLIP-Aware Pointing Ensemble module, which performs a hybrid ensemble guided by CLIP features. We further incorporate an auxiliary object center prediction head to enhance referent localization. We validate our approach on YouRefIt, achieving 75.0 mAP at 0.25 IoU, alongside state-of-the-art CLIP and C_D scores, and demonstrate its generality on unseen CAESAR and ISL Pointing, showing robust performance across benchmarks.
To overcome the limitations of rigid single-line pointing assumptions, our approach utilizes a dual-model framework designed to process multimodal cues and resolve referential ambiguity. The architecture consists of two parallel transformer-based networks—one guided by head-to-fingertip cues and the other by wrist-to-fingertip cues. Instead of relying on strict geometric lines that easily break due to occlusions or natural pose variations, we introduce Gaussian Ray Heatmaps to represent pointing directions as soft spatial probability distributions. These heatmaps are encoded efficiently using a lightweight ResNet-18, while the complex visual scene and spoken language instructions are processed by a ResNet-101 and RoBERTa, respectively. The multimodal features are then concatenated and fused within a Transformer Encoder-Decoder network. To guarantee highly precise target localization in dense environments, we further enhance the network with auxiliary supervisory tasks, including explicit object center prediction, gestural keypoint tracking, and a referent alignment loss.
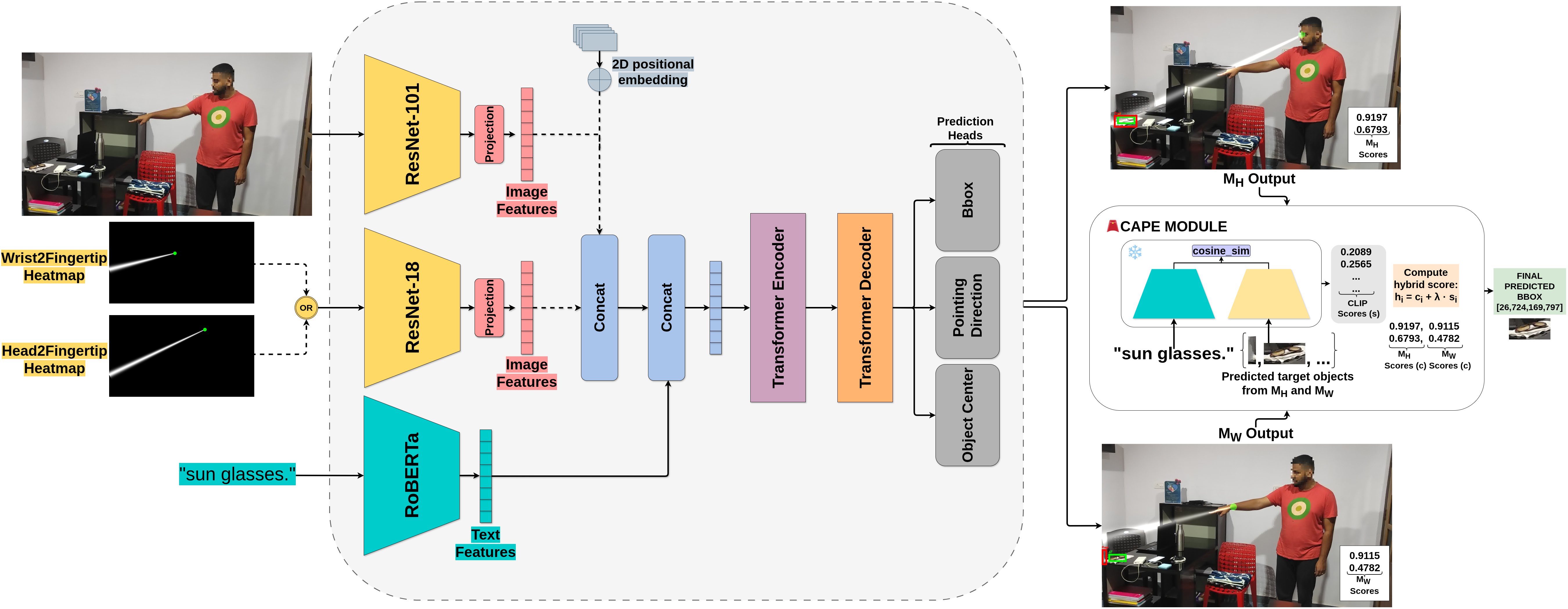
Because the head and wrist pointing directions offer complementary advantages depending on the user's pose and scene layout, we dynamically fuse the predictions of both models during inference using our novel CLIP-Aware Pointing Ensemble (CAPE) module. CAPE operates without any additional training overhead by leveraging a pre-trained CLIP model to compute image-text semantic similarity scores for the top bounding box candidates proposed by both networks. By intelligently balancing the spatial confidence scores of our pointing models with the deep semantic understanding of CLIP, the ensemble accurately selects the intended referent. Furthermore, CAPE employs a size-aware adaptation rule—summing model confidence with CLIP scores for extremely small targets where vision-language models typically struggle—ensuring highly robust, state-of-the-art object identification across diverse and complex real-world scenarios.
@inproceedings{eyiokur2026cape,
title={CAPE: A CLIP-Aware Pointing Ensemble of Complementary Heatmap Cues for Embodied Reference Understanding},
author={Eyiokur, Fevziye Irem and Yaman, Dogucan and Ekenel, Haz{\i}m Kemal and Waibel, Alexander},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={3939--3950},
year={2026}
}